[AI 리서치 자동화 2편] AI 리서치 스택 완전 비교: STORM, Deep Research, NotebookLM 그리고 내 블로그에 적용하기
본 포스팅은 AI 에이전트를 활용한 리서치 자동화 프레임워크들을 분석하고, 이를 블로그 자동화 및 콘텐츠 품질 향상에 실질적으로 적용하는 방법을 다루는 [AI 리서치 자동화] 2부작 시리즈의 두 번째 글입니다.
지난 1편에서는 카파시의 AutoResearch 프레임워크가 보여준 '자율 최적화 루프'라는 설계 패턴과, Software 3.0 시대에서 인간의 역할이 '실행자'에서 '설계자'로 전환되고 있음을 살펴보았습니다.
이번 2편에서는 AutoResearch의 설계 원리를 염두에 두고, 현재 가장 검증된 AI 리서치 프레임워크들을 비교 분석한 뒤, 이를 실제 블로그 자동화 파이프라인에 구체적으로 적용하는 방법을 제시하겠습니다.
1. 주요 AI 리서치 프레임워크 비교
 AI 리서치 도구 비교
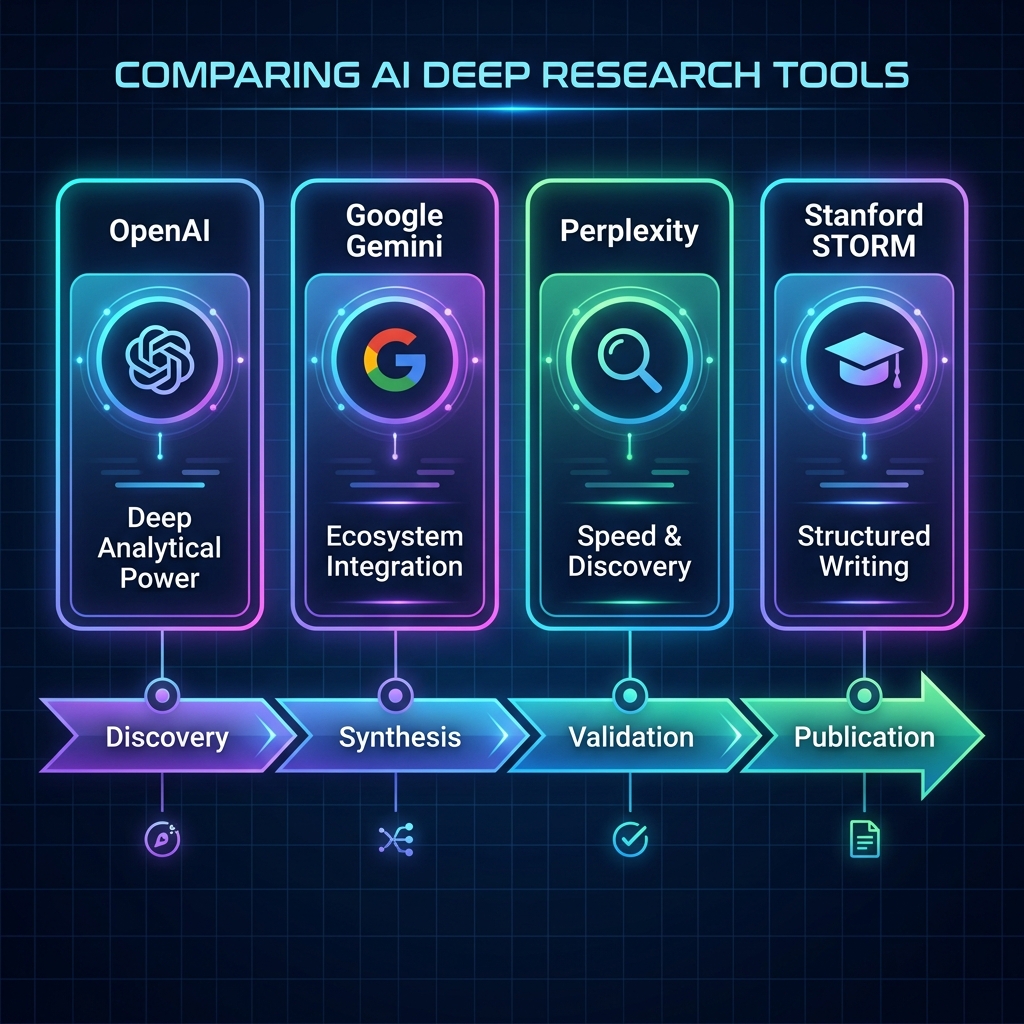
각 AI 리서치 도구는 Discovery(발견), Synthesis(종합), Validation(검증), Publication(발행)이라는 연구 파이프라인의 서로 다른 단계에서 강점을 발휘합니다. 하나의 도구만 쓰는 것이 아니라, 단계별로 적합한 도구를 조합하는 '리서치 스택'을 구축하는 것이 핵심입니다. (AI Generated)
AI 리서치 도구 비교
각 AI 리서치 도구는 Discovery(발견), Synthesis(종합), Validation(검증), Publication(발행)이라는 연구 파이프라인의 서로 다른 단계에서 강점을 발휘합니다. 하나의 도구만 쓰는 것이 아니라, 단계별로 적합한 도구를 조합하는 '리서치 스택'을 구축하는 것이 핵심입니다. (AI Generated)
① 스탠포드 STORM — 구조적 글쓰기의 정석
STORM(Synthesis of Topic Outlines through Retrieval and Multi-perspective Question Asking)은 스탠포드 대학교 OVAL 연구팀이 개발한 오픈소스 AI 글쓰기 프레임워크입니다.
STORM의 작동 원리:
- 관점 발견(Perspective Discovery): 주어진 주제에 대해 다양한 전문가 관점(예: 경제학자, 심리학자, 정책입안자)을 자동으로 식별합니다.
- 다관점 질문(Multi-perspective Q&A): 각 관점을 대표하는 AI 에이전트들이 서로에게 심층 질문을 던지며, 웹 검색과 논문 검색을 통해 답변을 수집합니다.
- 아웃라인 합성(Outline Synthesis): 수집된 정보를 논리적으로 구조화하여 상세한 글 목차를 생성합니다.
- 본문 작성(Article Writing): 검증된 출처와 구조화된 목차를 기반으로 인용이 포함된 장문의 글을 생성합니다.
장점: 할루시네이션 최소화(출처 기반 작성), 위키피디아급 구조적 글쓰기에 최적화, 오픈소스로 커스터마이징 가능. 한계: 설치 및 설정의 기술적 진입 장벽, 실시간 웹 정보 반영의 한계.
② OpenAI Deep Research — 분석적 깊이의 끝판왕
ChatGPT의 Deep Research 기능은 o3 추론 모델(Reasoning Model)을 기반으로, 복잡한 다단계 리서치를 자율적으로 수행합니다.
특징:
- 5~30분에 걸쳐 수십 개의 웹 소스를 탐색하고, 상충하는 증거를 교차 검증합니다.
- 코드 실행과 데이터 분석이 가능하여 기술적 리서치에 특히 강합니다.
- 각주(Footnote)가 달린 전문적인 장문 보고서를 출력합니다.
장점: 현존하는 AI 리서치 도구 중 가장 강력한 추론(Reasoning) 능력. 복잡한 학술 주제에 최적. 한계: 처리 시간이 길고, Pro 구독(월 $200)이 필요합니다.
③ Google NotebookLM — 생태계 통합의 워크호스
Google의 NotebookLM은 사용자가 업로드한 소스(PDF, 웹페이지, 유튜브 영상 등)를 기반으로 질의응답, 요약, 브리핑 문서, 팟캐스트(Audio Overview)를 자동 생성합니다.
특징:
- Gmail, Google Drive, Google Docs와 네이티브 통합되어 '내 자료' 기반 리서치에 강합니다.
- Deep Research 기능(웹/드라이브 검색)을 통해 새로운 소스를 자동으로 발굴합니다.
- 오디오, 비디오, 슬라이드 덱, 인포그래픽 등 다양한 형태의 산출물을 생성합니다.
장점: 이미 보유한 자료를 기반으로 한 리서치에 탁월. 구글 생태계 사용자에게 최적화. 한계: 업로드한 소스 외의 정보에 대해서는 별도 리서치가 필요합니다.
④ Perplexity — 속도와 발견의 스카우트
Perplexity는 AI 기반 검색 엔진으로, 실시간 웹 검색과 요약에 특화되어 있습니다.
특징:
- 15초~4분 내에 빠르게 소스를 발굴하고 요약합니다.
- 검색 결과마다 출처(Citation)를 명확하게 표시합니다.
- Pro Search 모드에서 다단계 심층 탐색을 지원합니다.
장점: 현존 최고 속도의 리서치 도구. 새로운 주제의 '지형도'를 빠르게 파악하는 데 최적. 한계: 장문의 구조적 리포트 생성에는 상대적으로 약합니다.
2. 리서치 프레임워크 비교표
| 기준 | Stanford STORM | OpenAI Deep Research | Google NotebookLM | Perplexity |
|---|---|---|---|---|
| 주요 강점 | 구조적 글쓰기 | 분석적 깊이 | 생태계 통합 | 속도 & 발견 |
| 처리 시간 | 5~15분 | 5~30분 | 2~15분 | 15초~4분 |
| 출력 형태 | 장문 아티클 | 학술 리포트 | 브리핑/오디오/슬라이드 | 요약 + 출처 리스트 |
| 오픈소스 | ✅ (GitHub) | ❌ | ❌ | ❌ |
| 할루시네이션 위험 | 낮음 (출처 기반) | 낮음 (추론 모델) | 낮음 (소스 고정) | 중간 |
| 가격 | 무료 (API 비용 별도) | $20~200/월 | 무료~$20/월 | 무료~$20/월 |
| 최적 활용 단계 | Synthesis + Writing | Synthesis + Validation | Integration + Publishing | Discovery |
3. 실전 적용: 내 블로그 자동화 파이프라인에 어떻게 적용할 것인가?
이제 이 프레임워크들을 실제 블로그 콘텐츠 제작 파이프라인에 적용하는 구체적인 방법을 단계별로 설명하겠습니다.
Stage 1. 발견 (Discovery) — Perplexity가 정찰병
새로운 블로그 주제를 정할 때, Perplexity를 사용하여 해당 주제의 "지형도(Landscape)"를 빠르게 그립니다.
- 사용 예시: "마시멜로 실험에 대한 최신 재현 연구와 비판"을 검색 → 15초 만에 핵심 논문 5개, 관련 뉴스 기사 10개, 주요 인물 리스트를 확보합니다.
- 목표: 어떤 하위 주제(Sub-topic)들이 존재하는지, 어떤 논쟁이 있는지, 핵심 출처가 무엇인지 빠르게 파악합니다.
Stage 2. 심층 리서치 (Deep Dive) — OpenAI 또는 NotebookLM이 잠수부
발견 단계에서 확보한 핵심 소스들을 기반으로, OpenAI Deep Research 또는 NotebookLM에 투입하여 심층 분석을 수행합니다.
- OpenAI Deep Research 활용: "Mullainathan & Shafir의 Scarcity 이론과 Mischel의 마시멜로 실험 사이의 연관성을 분석하라"와 같은 복잡한 분석적 질문을 던집니다.
- NotebookLM 활용: 확보한 PDF 논문, 유튜브 강의, 웹페이지를 모두 소스로 업로드한 뒤, "이 소스들 전체를 종합하여 핵심 논쟁과 합의점을 정리하라"고 질의합니다.
- 목표: 단순한 사실 나열을 넘어, 소스 간의 모순점, 합의점, 그리고 아직 탐구되지 않은 빈틈(Gap)을 발견합니다.
Stage 3. 구조화 & 초안 (Structuring & Drafting) — STORM 패턴 적용
심층 리서치의 결과물을 바탕으로, STORM의 '다관점 아웃라인 생성' 패턴을 적용하여 글의 골격을 잡습니다.
- STORM 패턴 적용 예시:
- 관점 1 (심리학자): "자기 통제력은 선천적인가, 환경적인가?"
- 관점 2 (행동경제학자): "빈곤은 인지적 대역폭을 어떻게 소모하는가?"
- 관점 3 (정책입안자): "이 연구 결과는 복지 정책에 어떤 시사점을 주는가?"
- 목표: 단일 시각에 갇히지 않고, 독자에게 입체적이고 풍부한 관점을 제공하는 글 구조를 설계합니다.
Stage 4. 카파시 루프 적용 (Quality Optimization) — 검증 가능한 지표로 반복 개선
여기서 카파시의 AutoResearch 루프 패턴이 빛을 발합니다. 초안이 완성된 후, 다음과 같은 자동 검증 루프를 돌립니다.
- 나의
program.md(블로그 품질 지침서) 예시:## 블로그 포스트 품질 기준 - [ ] 모든 핵심 주장에 출처(논문, 뉴스 기사)가 있는가? - [ ] 참고자료 섹션에 최소 3개 이상의 학술 논문이 포함되어 있는가? - [ ] SEO: title, description, tags가 모두 채워져 있는가? - [ ] 글의 분량이 최소 2,000자 이상인가? - [ ] 내부 링크(시리즈 내 다른 글)가 최소 1개 이상 포함되어 있는가? - [ ] 이미지가 최소 1개 이상 포함되어 있는가? - 루프 실행: AI 에이전트가 초안을 이 체크리스트에 대해 자동으로 검증합니다. 기준을 충족하지 못한 항목이 있으면 자동으로 수정하고 다시 검증합니다.
- 목표: 인간이 매번 수동으로 체크하지 않아도, 일정 수준 이상의 품질이 '자동으로' 보장되는 시스템을 구축합니다.
Stage 5. 발행 & 배포 (Publishing) — GitHub Actions 자동화
최종 검증을 통과한 포스트는 GitHub에 자동으로 커밋 & 푸시되어 블로그에 배포됩니다. 이 단계는 이미 우리 블로그의 Daily AI News 파이프라인에서 GitHub Actions를 통해 구현되어 있습니다.
4. 현재 내 블로그 파이프라인의 위치와 개선 방향
현재 우리 블로그 시스템은 이미 다음과 같은 자동화를 갖추고 있습니다:
| 단계 | 현재 상태 | 개선 방향 |
|---|---|---|
| 발견 | 수동 또는 RSS 기반 | Perplexity API 연동으로 자동 주제 발굴 |
| 심층 리서치 | NotebookLM 수동 활용 | NotebookLM MCP + Deep Research 자동화 |
| 구조화 | AI 에이전트가 단일 관점으로 작성 | STORM 패턴 적용 (다관점 아웃라인) |
| 품질 검증 | 인간이 수동 리뷰 | program.md 기반 자동 검증 루프 도입 |
| 배포 | GitHub Actions 자동화 ✅ | 유지 |
가장 큰 개선 기회는 Stage 3(구조화)과 Stage 4(품질 검증)에 있습니다. STORM의 다관점 패턴을 적용하면 글의 깊이가 한 차원 높아지고, 카파시 루프 패턴의 자동 검증을 적용하면 일정한 품질 수준이 기계적으로 보장됩니다.
5. 핵심 교훈: "도구를 쓰되, 판단은 사람이 한다"
이 모든 프레임워크의 공통점은 하나입니다. AI는 '실행의 속도'를 극적으로 끌어올리지만, '판단의 질'은 여전히 인간에게 달려 있다는 것.
카파시가 강조한 "Taste(안목)", STORM이 요구하는 "다양한 관점의 설계", 그리고 Deep Research가 제공하는 "증거 기반의 교차 검증" — 이 모든 것의 최종 품질 관문(Quality Gate)은 결국 "이 결과물이 정말 가치 있는가?"를 판단하는 인간의 눈입니다.
AI 리서치 도구는 우리에게 10배의 속도와 100배의 탐색 범위를 줍니다. 하지만 그 결과물을 독자에게 전달할 가치가 있는 콘텐츠로 만드는 것은, 여전히 글을 쓰는 사람의 몫입니다.
📚 참고자료
- Shao, Y., Jiang, Y., Kanell, T., Xu, P., Khashabi, D., & Callison-Burch, C. (2024). Assisting in Writing Wikipedia-like Articles From Scratch with Large Language Models (STORM). Stanford OVAL. storm-project.stanford.edu
- Karpathy, A. (2026). AutoResearch Framework. GitHub Repository
- OpenAI (2025). Introducing Deep Research. openai.com
- Google (2025). NotebookLM: Your AI research assistant. notebooklm.google.com
- Perplexity AI (2025). Pro Search: Multi-step AI Research. perplexity.ai
- McKinsey & Company (2025). The state of AI in early 2025. mckinsey.com
💡 AI Learnings 의 다른 글
전체보기→[AI 개발 자동화] Gemini CLI Superpowers 완벽 가이드 및 실전 유스케이스
단순한 터미널 챗봇을 완벽하게 규율 잡힌 시니어 엔지니어로 바꿔주는 Gemini CLI Superpowers 확장의 14가지 핵심 스킬과 실전 활용법을 소개합니다.
[Antigravity 활용 가이드 3] 오픈소스 Skill로 코딩 자동화 파이프라인 구축하기
Gemini CLI의 꽃이라 할 수 있는 Skill 시스템을 이해하고, 오픈소스로 공개된 다양한 스킬을 확장하여 강력한 코딩 자동화 워크플로우를 구축하는 방법을 알아봅니다.
[AI 개발의 미래] Gemini CLI Superpowers vs Antigravity 에이전트 전격 비교
최근 인공지능(AI) 코딩 어시스턴트 시장은 단순한 '코드 자동 완성' 시대를 넘어, 개발자의 워크플로우를 주도적으로 설계하고 실행하는 **'에이전트 기반(Agentic) 개발'** 시대로 접어들었습니다 [1]. 그 중심에는 터미널 환경을 AI 통합 워크스페이스로 변모...
[AI 개발의 혁신] FastMCP란 무엇이며, 왜 사용해야 하는가?
**MCP(Model Context Protocol)**는 대규모 언어 모델(LLM)을 외부 데이터 소스 및 도구와 안전하게 연결해주는 개방형 표준 프로토콜로, 종종 'AI를 위한 USB-C 포트'에 비유됩니다 [1, 2]. 하지만 이 프로토콜의 스펙을 직접 구현하는...
Model Context Protocol (MCP) 완벽 가이드: AI 에이전트 통합의 새로운 표준
**Model Context Protocol (MCP)**는 2024년 11월 Anthropic이 발표한 오픈 소스 표준으로, AI 애플리케이션이 외부 시스템 및 데이터 소스와 원활하고 안전하게 연결될 수 있도록 돕는 범용 프로토콜입니다 [1], [2]. 과거에는 A...
[Antigravity 활용 가이드 2] 토큰 한계를 넘는 비법: YOLO 모드와 청킹(Chunking)
Gemini CLI의 강력한 기능인 YOLO 모드를 활용한 브레인스토밍 이터레이션 기법과 제한된 컨텍스트 윈도우를 효율적으로 극복하는 청킹(Chunking) 기술을 소개합니다.
[Antigravity 활용 가이드 1] Antigravity와 Gemini CLI, 어떻게 다르게 써야 할까?
Agentic AI 코딩 어시스턴트인 Antigravity와 강력한 터미널 도구인 Gemini CLI의 차이점을 알아보고, 각 도구를 어떤 상황에서 어떻게 활용해야 완벽한 시너지를 낼 수 있는지 분석합니다.