숫자는 완벽하게 똑같은데, 그래프는 완전히 다르다? 요약 데이터의 함정 '앤스컴의 콰르텟 (Anscombe's Quartet)'
회사에서 보고서를 작성하거나 데이터를 분석할 때, 우리는 흔히 수많은 데이터를 몇 개의 숫자로 압축하여 표현합니다. "올해 우리 고객들의 평균 연령은 35세입니다." "마케팅 비용과 매출의 상관계수는 0.8로 매우 높습니다."
이렇게 평균(Mean), 분산(Variance), 상관계수(Correlation) 같은 숫자로 데이터를 뭉뚱그려 표현하는 것을 '요약 통계(Summary Statistics)'라고 합니다. 아주 편리하고 직관적이죠.
하지만 1973년, 영국의 통계학자 프랭시스 앤스컴(Francis Anscombe)은 "숫자만 믿고 데이터를 다 아는 척하는 당신, 크게 다칠 수 있다"고 경고하며, 아주 기괴하고 충격적인 4개의 데이터 세트를 발표합니다.
🎭 1. 완벽하게 똑같은 쌍둥이 숫자들
앤스컴이 만든 4개의 데이터 세트(Dataset I, II, III, IV)는 각각 11개의 X, Y 좌표로 이루어져 있습니다. 놀랍게도, 이 4개의 데이터 세트를 컴퓨터 프로그램이나 엑셀에 넣고 요약 통계를 돌려보면 소수점 둘째 자리까지 완벽하게 일치하는 결과가 나옵니다.
- X의 평균: 9.00
- Y의 평균: 7.50
- X의 분산: 11.00
- Y의 분산: 4.125
- X와 Y의 상관계수: 0.816 (매우 강한 양의 상관관계)
- 선형 회귀 방정식: Y = 3.00 + 0.50X
숫자만 보면 이 4개의 데이터는 서로 구분할 수 없는 완벽한 쌍둥이입니다. 보고서를 받는 상사나, 알고리즘을 학습시키는 AI 모델 입장에서는 "음, 4개 다 똑같은 성질을 가진 데이터군" 하고 넘어가기 십상입니다.
👁️ 2. 시각화가 폭로한 충격적인 반전
앤스컴은 이렇게 말합니다. "숫자만 보지 말고, 당장 그 데이터를 점으로 찍어 그래프(Scatter Plot)로 그려보시오."
명령대로 4개의 데이터를 시각화하는 순간, 믿을 수 없는 반전이 펼쳐집니다.
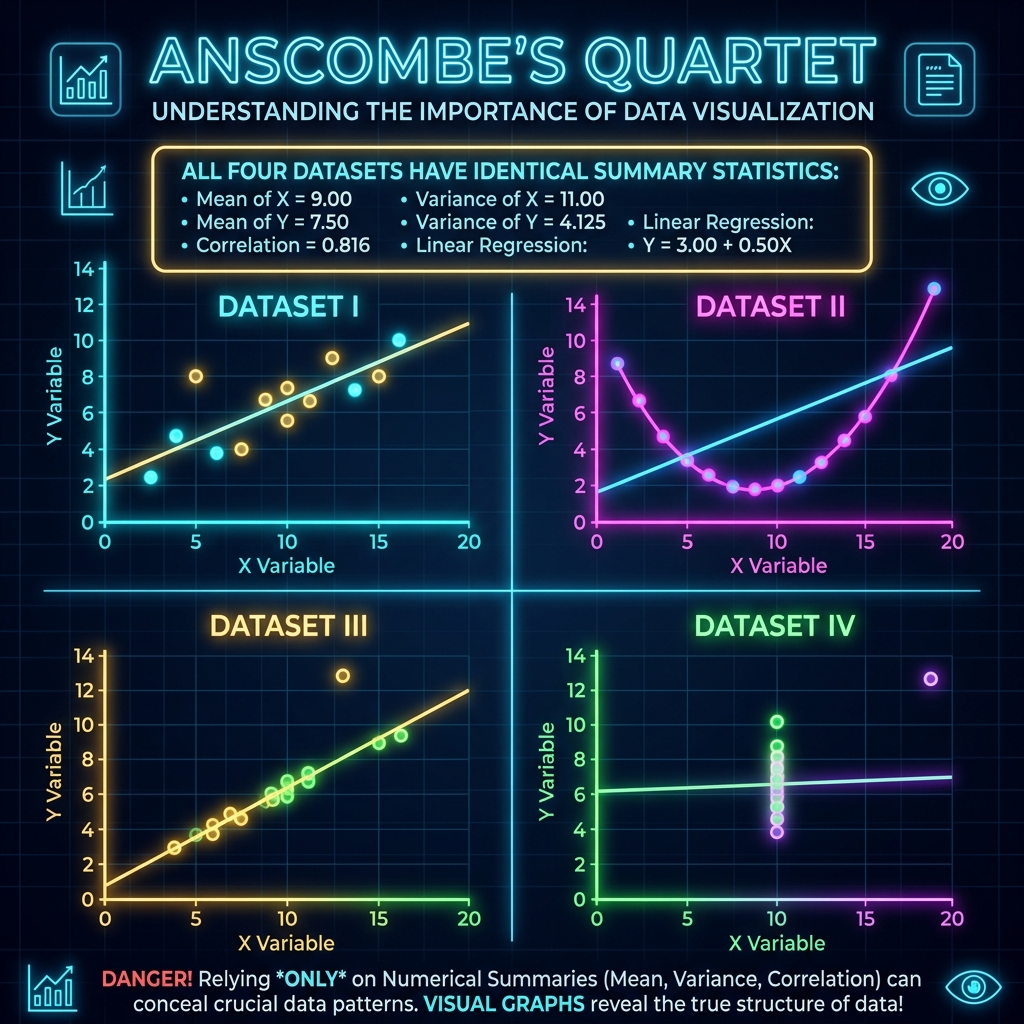 앤스컴의 콰르텟 인포그래픽
(숫자는 완벽히 동일하지만, 그래프로 그리는 순간 드러나는 4가지 완전히 다른 형태의 데이터 구조)
앤스컴의 콰르텟 인포그래픽
(숫자는 완벽히 동일하지만, 그래프로 그리는 순간 드러나는 4가지 완전히 다른 형태의 데이터 구조)
- 데이터 I: 우리가 흔히 예상하는 이상적이고 정상적인 선형 관계(Linear)입니다. 점들이 회귀선 주위에 골고루 퍼져 있습니다.
- 데이터 II: 직선이 아니라 완벽한 2차 곡선(U자 형태)입니다! 상관계수 수치는 0.816이었지만, 이 데이터는 직선의 관계를 가지지 않습니다. 선형 회귀 모델을 적용하면 완벽하게 망하게 됩니다.
- 데이터 III: 완벽한 직선 위에 점들이 놓여 있지만, 딱 하나의 극단적인 이상치(Outlier)가 전체 회귀선을 위로 끌어당기고 있습니다.
- 데이터 IV: X값이 8인 곳에 모든 점이 수직으로 몰려 있습니다. X와 Y는 아무런 관계가 없는데, 우측 상단에 뚝 떨어져 있는 단 하나의 튀는 점(Outlier) 때문에 상관계수가 0.816이라는 높은 수치로 둔갑해 버렸습니다.
🚨 3. 요약 데이터가 숨기고 있는 함정
이 4개의 그래프(앤스컴의 콰르텟)가 데이터 사이언티스트들에게 주는 교훈은 뼈아플 정도로 명확합니다.
- 숫자는 데이터를 요약할 뿐, 전체 구조를 말해주지 않는다. 평균과 분산은 데이터를 설명하는 데 훌륭한 도구이지만, 그 안에 숨어 있는 곡선 패턴이나 이상치(Outlier)의 존재를 완벽하게 은폐해 버립니다.
- 단 하나의 튀는 데이터가 전체 결론을 오염시킨다. 데이터 III과 IV를 보면, 수많은 정상적인 데이터들이 단 한 개의 극단적인 이상치(Outlier) 때문에 평균과 상관계수가 심각하게 왜곡되는 것을 볼 수 있습니다. 만약 시각화를 하지 않았다면, 분석가는 이 거짓된 수치에 속아 잘못된 의사결정을 내렸을 것입니다.
- 데이터 시각화는 '꾸미기'가 아니라 '분석의 첫걸음'이다. 많은 사람들이 분석을 다 끝낸 뒤 보고서를 예쁘게 꾸미기 위해 그래프를 그립니다. 하지만 앤스컴의 콰르텟은 "통계 모델을 돌리기 전에, 가장 먼저 눈으로 데이터를 그려보고 직관적으로 확인해야 한다"고 가르칩니다.
💡 4. '공룡 무늬' 데이터의 등장 (Datasaurus Dozen)
시간이 흘러 2017년, 컴퓨터 그래픽 기술이 발달하면서 앤스컴의 콰르텟은 '데이터사우루스 다즌(Datasaurus Dozen)'이라는 형태로 진화합니다. 이 데이터들은 평균, 분산, 상관계수가 소수점 두 자리까지 모두 똑같습니다. 하지만 점들을 찍어보면 어떤 것은 별 모양(★), 어떤 것은 십자가 모양(✚), 심지어 티라노사우루스 공룡 모양(🦖)의 그래프가 나타납니다.
빅데이터 시대, 숫자에 파묻혀 허우적대고 있다면 잠시 키보드에서 손을 떼고 모니터에 점을 찍어보세요. 숫자가 차마 말하지 못했던 진실이, 때로는 공룡의 모습으로 당신에게 손을 흔들고 있을지도 모릅니다.
📚 참고자료 및 주석
- Francis Anscombe (1973), "Graphs in Statistical Analysis"
- 앤스컴의 콰르텟 (Anscombe's Quartet) 및 Datasaurus Dozen
A/B 테스트와 통계적 유의성의 함정: p-value의 진실과 가짜 승리(False Positive) 피하기
현대 디지털 비즈니스에서 직관에 의존한 의사결정은 도박과 같습니다. 넷플릭스, 구글, 아마존과 같은 기업들이 성장을 멈추지 않는 이유는 천재적인 기획자 덕분이 아니라, 수천 개의 가설을 동시에 검증하는 강력한 **A/B 테스트(A/B Testing)** 인프라 덕분입니...
Vibe Coding 기반 광고 낭비 감시 자동화 시스템 구축 (n8n, Antigravity)
지금까지 11편의 포스트를 통해 디지털 마케팅에 숨겨진 거대한 예산 낭비 구멍(Cannibalization, MFA, 봇 트래픽, PMax 블랙박스 등)을 파헤쳤습니다. 이론을 알았다면 이제 남은 것은 단 하나, **실행(Execution)**입니다. 하지만 데이터 엔...
AI에 끌려가지 않는 '신호 설계자(Signal Designer)' 전략
구글 PMax(Performance Max)나 메타 Advantage+와 같은 극단적 자동화 캠페인의 시대입니다. 타겟팅, 입찰, 게재 위치 심지어 광고 소재 조립까지 AI가 다 알아서 해주는 세상에서 **"마케터의 새로운 역할은 무엇인가?"**라는 질문이 쏟아지고 있...
전문가도 속는 통계 오류: 상관/인과, 교란 변수, 유의성의 함정
"데이터는 거짓말을 하지 않는다." 마케터들이 흔히 하는 착각입니다. 데이터 자체는 거짓말을 하지 않을지 몰라도, **그 데이터를 해석하는 사람은 매일 거짓말에 속아 넘어갑니다.** 오늘은 마케터의 데이터 리터러시(Data Literacy)를 시험하는 가장 무서운 통계...
우리가 믿었던 '공부법'의 배신: 데이터가 폭로한 3가지 학습 신화
"사람은 각자 타고난 학습 스타일이 있다." "교과서에 형광펜으로 밑줄을 그으며 반복해서 읽는 것이 최고다." "어떤 분야든 1만 시간을 투자하면 세계적인 전문가가 될 수 있다." 우리는 살면서 이런 조언들을 무수히 듣고 자랐습니다. 하지만 데이터와 인지과학의 세계...
8만 명 중 1등 — 한국 대학생이 세계 퀀트 대회를 제패한 '32개 알고리즘'의 비밀
142개국 8만 명이 참가한 국제 퀀트 챔피언십(IQC)에서 UNIST 김민겸 학생이 한국인 최초로 우승했다. 200개 넘는 알고리즘 대신 32개만 쓴 그의 전략, 그리고 AI 시대 퀀트 투자의 본질을 분석한다.
하루 8잔? 물에 관한 가장 유명한 건강 신화의 탄생과 붕괴
우리가 수십 년간 믿어온 '하루 물 8잔' 규칙은 어디서 왔을까요? 1945년 단 하나의 보고서에서 시작된 거대한 오해가 과학, 미디어, 상업적 이해관계를 거쳐 어떻게 '건강 상식'으로 둔갑했는지, 그리고 누가 이 신화를 무너뜨렸는지 추적합니다.