왜 AI가 점점 멍청해지는 걸까? — Gemini 3.1 Pro의 답 누락과 Claude Opus 4.6의 토큰 한도 에러 분석
최근 1주일간, AI를 집중적으로 활용하는 사용자들 사이에서 공통된 불만이 급증하고 있다.
"Gemini 3.1 Pro가 요청한 작업 중 일부를 자꾸 빠뜨린다." "Claude Opus 4.6이 Token limit exceeded 에러를 너무 자주 낸다."
단순한 서버 불안정이 아니다. 이 현상들의 이면에는 최신 LLM이 직면한 구조적 한계와 경제적 압박이 숨어 있다. 왜 이런 일이 발생하는지, 그리고 어떻게 대응해야 하는지를 분석한다.
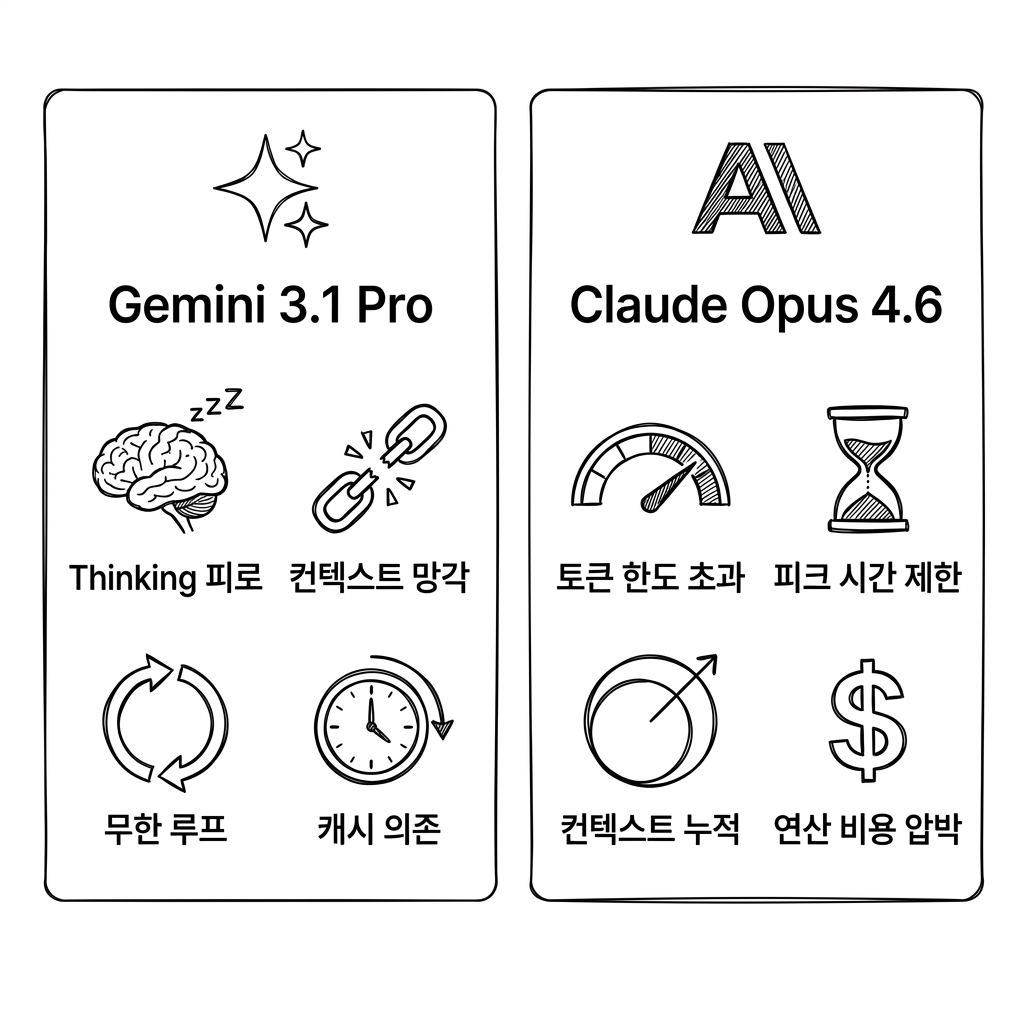 Gemini 3.1 Pro와 Claude Opus 4.6의 주요 이슈 비교 — Thinking 피로, 컨텍스트 망각, 토큰 한도 초과, 연산 비용 압박
Gemini 3.1 Pro와 Claude Opus 4.6의 주요 이슈 비교 — Thinking 피로, 컨텍스트 망각, 토큰 한도 초과, 연산 비용 압박
🔴 증상 1: Gemini 3.1 Pro — "왜 시킨 것을 빠뜨릴까?"
보고된 주요 증상들
2026년 2월 출시 이후, Gemini 3.1 Pro에 대한 사용자 보고가 Reddit, Google AI 포럼, GitHub에 꾸준히 올라오고 있다. 핵심 증상은 4가지로 분류된다.
| 증상 | 설명 | 발생 조건 |
|---|---|---|
| Thinking 피로 | Deep Think 추론이 대화 후반부에서 작동을 멈추고, 성급하고 부정확한 답변을 생성 | 긴 대화 세션 (20~25번 이상의 주고받기) |
| 컨텍스트 망각 | 앞서 제공한 정보를 "그런 정보를 받은 적 없다"며 부정 | 100만 토큰 컨텍스트 윈도우 내에서도 발생 |
| 무한 루프 | "Thinking..." 상태에서 60~90초 이상 멈추고 최종 응답을 내지 않음 | 복잡한 멀티 도구 워크플로우 |
| 캐시 의존(Cached Laziness) | 실시간 검색 대신 오래된 캐시 데이터에 의존하여 부정확한 정보 제공 | 최신 정보가 필요한 질문 |
왜 이런 일이 벌어지는가?
원인 1: "Deep Think" 아키텍처의 이중성
Gemini 3.1 Pro의 가장 큰 특징은 Deep Think — 답변하기 전에 내부적으로 깊이 '사고'하는 추론 프로세스다. 벤치마크에서는 이 기능이 정확도를 크게 높여주지만, 실전에서는 두 가지 문제를 야기한다:
- 추론 과부하: 대화가 길어질수록 Deep Think가 처리해야 할 컨텍스트가 기하급수적으로 늘어난다. 일정 임계치를 넘으면 추론 엔진이 '포기'하고 얕은 답변으로 전환된다.
- 요약 병목: 일부 분석에 따르면, Google은 Deep Think의 내부 사고 토큰을 더 작고 빠른 모델로 요약하여 속도를 높이는 전략을 쓰고 있다. 이 과정에서 핵심 정보가 누락될 수 있다.
비유하자면: 100페이지짜리 보고서를 읽고 분석하라는 과제를 받았는데, 시간이 부족하자 끝부분만 대충 훑어보고 답안을 제출하는 학생과 같다.
원인 2: 인프라 과부하
개발자들은 피크 시간대에 503 에러가 빈번하게 발생한다고 보고하고 있다. 이는 모델의 수요가 가용 컴퓨팅 자원을 초과하고 있음을 시사한다. Preview 단계의 모델에서 특히 심각한 문제다.
원인 3: 사고 블록 누출(Thought Block Leak)
일부 사용자들은 모델이 내부 추론 과정(<thought> 블록)을 날것 그대로 출력하거나, "Done" 메시지를 반복적으로 내보내는 재귀 루프에 빠지는 현상을 보고했다.
🟡 증상 2: Claude Opus 4.6 — "왜 자꾸 토큰 한도 에러가 날까?"
보고된 주요 증상들
2026년 2월 5일 출시된 Claude Opus 4.6에서 사용자들이 가장 많이 경험하는 에러는 "Token limit exceeded"다. 이 에러의 빈도가 최근 급격히 높아진 데에는 여러 원인이 복합적으로 작용하고 있다.
| 증상 | 설명 | 발생 조건 |
|---|---|---|
| 토큰 한도 초과 | 세션 중간에 갑자기 응답 불가 | 복잡한 멀티 스텝 에이전트 작업 |
| 피크 시간 제한 | 특정 시간대에 더 빈번한 한도 도달 | 미국 서부 기준 오전 5시~11시(PT) |
| 응답 조기 종료 | Extended Thinking 모드에서 답변이 중간에 잘리는 현상 | Thinking 예산 소진 시 |
| 누적 비용 폭발 | 긴 대화에서 갑자기 한도에 도달 | 30턴 이상의 장기 세션 |
왜 이런 일이 벌어지는가?
원인 1: "보이지 않는 토큰 소비" — 컨텍스트 재처리
대부분의 사용자가 간과하는 핵심 사실이 있다:
매 턴(turn)마다, 모델은 이전 대화 전체를 다시 읽는다.
5번째 메시지를 보낼 때, 모델은 14번째 메시지를 모두 다시 처리한다. 10번째 메시지를 보낼 때는 19번째를 전부. 대화가 길어질수록 토큰 소비량은 선형이 아니라 누적적으로 폭발한다.
예를 들어, 매 턴 평균 2,000 토큰을 주고받는다고 가정하면:
| 턴 수 | 그 턴에 소비되는 토큰 | 누적 총 토큰 |
|---|---|---|
| 1 | 2,000 | 2,000 |
| 5 | 10,000 | 30,000 |
| 10 | 20,000 | 110,000 |
| 20 | 40,000 | 420,000 |
| 30 | 60,000 | 930,000 |
30턴이면 거의 100만 토큰을 소비한다. 여기에 시스템 프롬프트, 도구 정의, Extended Thinking 토큰까지 더하면 한도에 도달하는 것은 시간 문제다.
원인 2: Extended Thinking의 숨겨진 비용
Extended Thinking(확장 사고) 모드는 Claude가 더 깊이 추론하도록 해주지만, 사고 과정 자체가 대량의 토큰을 소비한다. 사용자에게는 최종 답변만 보이지만, 내부적으로는 수천~수만 토큰의 '사고 토큰'이 생성되고 이것이 전부 할당량에 포함된다.
원인 3: 의도적인 수요 관리
Anthropic은 높은 수요를 관리하기 위해 의도적으로 세션 한도를 강화했다고 확인했다. 특히 피크 시간(PT 기준 오전 5~11시)에는 더 엄격한 제한이 적용된다. 이는 서비스의 안정성을 유지하기 위한 불가피한 선택이다.
🔄 공통 원인: LLM 성능 저하의 구조적 메커니즘
Gemini와 Claude의 증상은 다르지만, 근본 원인은 놀랍도록 유사하다.
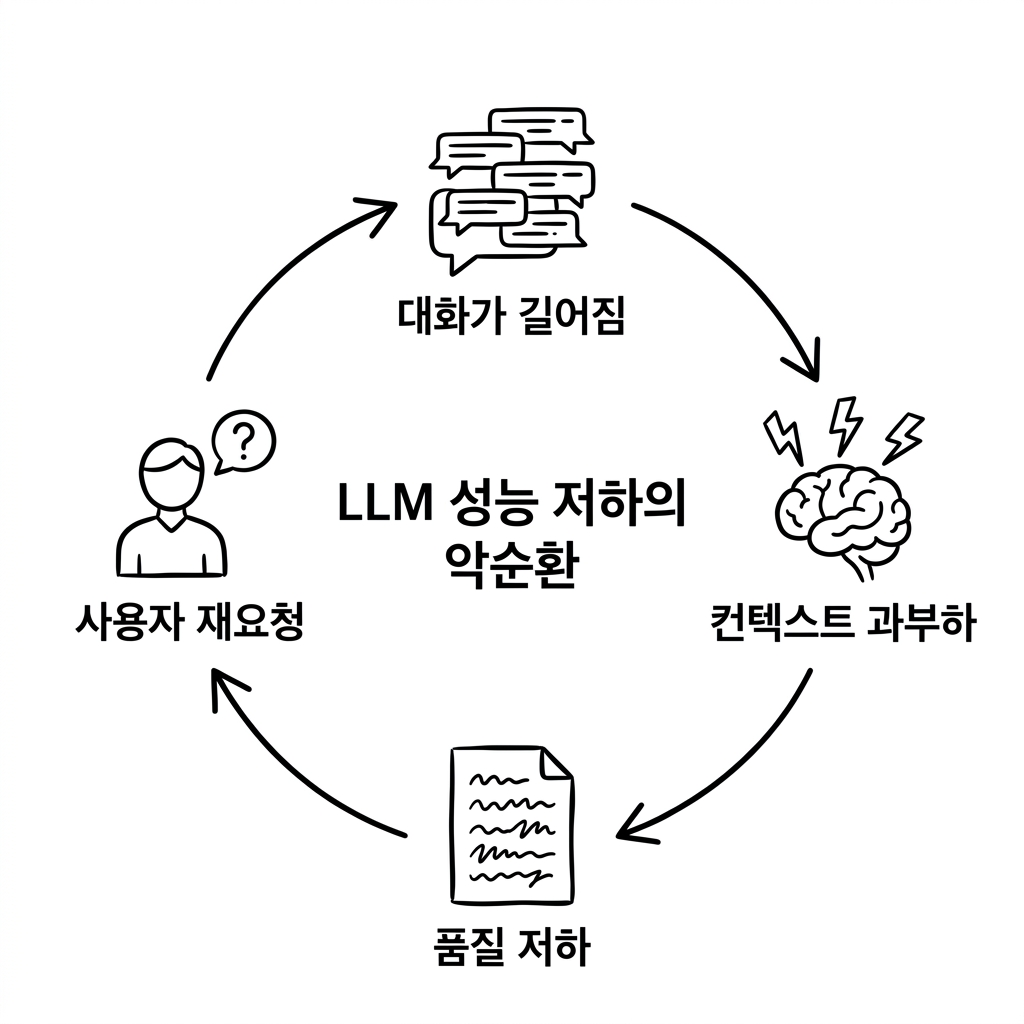 LLM 성능 저하의 악순환 — 대화가 길어짐 → 컨텍스트 과부하 → 품질 저하 → 사용자 재요청 → 대화가 더 길어짐
LLM 성능 저하의 악순환 — 대화가 길어짐 → 컨텍스트 과부하 → 품질 저하 → 사용자 재요청 → 대화가 더 길어짐
1. 컨텍스트 윈도우의 함정
"100만 토큰 컨텍스트 윈도우"는 마케팅적으로는 인상적이지만, 실제 성능은 컨텍스트 크기에 반비례하는 경향이 있다. 이를 'Lost in the Middle' 현상이라 부른다. 컨텍스트가 커질수록 모델은 중간 부분의 정보를 놓치는 경향이 강해진다.
2. 추론 비용(Inference Cost)의 경제학
LLM 서비스를 제공하는 것은 극도로 비싸다. 제공업체들은 비용을 관리하기 위해 다양한 '최적화'를 시도한다:
- 적극적 양자화(Quantization): 모델 정밀도를 낮춰 연산량을 줄이는 기법. 부작용으로 출력 품질이 저하될 수 있다.
- Thinking 요약: Deep Think의 전체 사고 과정을 작은 모델로 압축. 속도는 올라가지만 정보 손실 발생.
- 서버 용량 제한: 피크 시간대에 사용자당 할당량을 줄여 전체 서비스 안정성 유지.
3. 모델 드리프트(Model Drift)
LLM은 출시 후에도 끊임없이 업데이트된다. 안전 필터 강화, RLHF(인간 피드백 기반 강화학습) 정책 변경, 성능 최적화 패치 등이 수시로 적용된다. 이러한 '정렬(Alignment)' 업데이트가 특정 작업(특히 코딩, 창의적 글쓰기)에서 의도치 않은 성능 저하를 야기할 수 있다.
4. 모델 붕괴(Model Collapse) 위험
인터넷이 AI 생성 콘텐츠로 포화되면서, 새로운 모델의 학습 데이터에 다른 AI가 생성한 텍스트가 섞여 들어가는 비율이 높아지고 있다. 이 '합성 데이터의 재활용'은 다양성과 품질의 점진적 하락 — 이른바 '모델 붕괴' — 을 초래할 수 있다.
🛠️ 실전 대응 전략: 지금 바로 적용 가능한 팁
Gemini 3.1 Pro 사용자를 위한 대응법
| 전략 | 구체적 방법 | 효과 |
|---|---|---|
| 새 세션 시작 | 20~25턴 이후에는 새 대화 시작 | 컨텍스트 과부하 방지 |
| 하드 리프레시 | Ctrl+F5 + 쿠키 삭제 (gemini.google.com) | 세션 토큰 초기화 |
| 모델 토글 | Flash로 전환 → "Hi" 전송 → 다시 Pro로 복귀 | 연결 상태 리셋 |
| 간결한 프롬프트 | 복잡한 프롬프트 엔지니어링 대신 직접적이고 명확한 지시 | Deep Think 과부하 방지 |
| max_output_tokens 설정 | API 사용 시 출력 토큰 한도를 명시적으로 설정 | 무한 루프 방지 |
Claude Opus 4.6 사용자를 위한 대응법
| 전략 | 구체적 방법 | 효과 |
|---|---|---|
| 잦은 새 대화 | 주제 전환 시 반드시 새 세션 시작 | 누적 토큰 폭발 방지 |
| 모델 선택 최적화 | 복잡한 작업만 Opus, 일반 작업은 Sonnet, 경량 작업은 Haiku | 토큰 소비 분산 |
| Effort 레벨 조절 | Extra High/Max 대신 High 사용 | Thinking 토큰 절약 |
| 피크 시간 회피 | PT 기준 오전 5~11시 외 시간대 활용 | 한도 제한 완화 |
| 컨텍스트 최소화 | 필요한 정보만 전달, 불필요한 파일 참조 제거 | 입력 토큰 절감 |
| 시스템 프롬프트 경량화 | CLAUDE.md 등을 간결하게 유지 | 고정 오버헤드 절감 |
두 모델 공통 전략
"20턴 규칙"을 기억하라. 대화가 20턴을 넘어가면, 어떤 모델이든 성능이 저하되기 시작한다. 작업 단위를 작게 나누고, 완료될 때마다 새 세션을 시작하는 것이 가장 효과적인 방어책이다.
💡 이 현상이 주는 인사이트
1. 벤치마크 ≠ 실전 성능
Gemini 3.1 Pro는 벤치마크에서 압도적인 점수를 기록했지만, 실제 사용 환경에서는 안정성 문제로 고전하고 있다. 벤치마크는 통제된 환경에서의 단발성 테스트이며, 30턴 이상의 장기 세션, 멀티 도구 워크플로우, 피크 시간대 부하 등 실전 조건을 반영하지 못한다.
2. "더 큰 컨텍스트 윈도우"가 만능이 아니다
100만 토큰 컨텍스트 윈도우는 "더 많은 정보를 처리할 수 있다"는 의미이지, "더 잘 처리한다"는 의미가 아니다. 오히려 컨텍스트가 커질수록 중간 정보 누락(Lost in the Middle), 추론 비용 급증, 응답 품질 저하가 발생한다.
3. AI 서비스는 '공유 자원'이다
Claude의 토큰 한도 에러는 결국 수요와 공급의 문제다. 모든 사용자가 최고 성능 모델(Opus)을 최대 강도(Max Effort)로 사용하면, 인프라가 감당할 수 없다. 이는 도로 위의 교통 체증과 같다 — 모든 차가 고속도로에 몰리면 아무도 빨리 갈 수 없다.
4. AI 사용도 '습관'이 중요하다
가장 효과적인 AI 활용법은 가장 비싼 모델을 가장 오래 쓰는 것이 아니라, 작업에 맞는 모델을 짧고 집중적으로 쓰는 것이다. 마치 에스프레소 한 잔이 아메리카노 10잔보다 효과적인 것처럼.
🔮 전망: 이 문제는 해결될까?
단기적으로는 인프라 확충과 모델 안정화 패치를 통해 개선될 것이다. Google은 이미 Gemini의 무한 루프 문제에 대해 공식 버그 리포트를 접수하고 있으며, Anthropic도 피크 시간 관리 정책을 지속적으로 조정하고 있다.
하지만 장기적으로, 이 문제는 LLM 아키텍처의 근본적 한계와 맞닿아 있다. 추론은 비싸고, 컨텍스트는 유한하며, 수요는 무한하다. 이 삼중 모순을 해결하기 위한 차세대 아키텍처 — 더 효율적인 어텐션 메커니즘, 진정한 장기 기억(Long-term Memory), 그리고 지속 가능한 추론 비용 모델 — 가 등장하기 전까지는, "AI가 점점 멍청해지는" 경험은 피할 수 없는 현실이다.
그때까지 우리가 할 수 있는 최선은, AI의 한계를 이해하고 그에 맞는 사용 습관을 기르는 것이다.
📚 참고자료
- Google AI Developer Forum — Gemini 3.1 Pro 관련 버그 리포트 및 사용자 토론, 2026
- Reddit r/GoogleGemini — "Gemini 3.1 Pro thinking fatigue and context failures", 2026
- GitHub Issues — Gemini API Infinite Loop 관련 이슈 트래커, 2026
- Anthropic 공식 문서 — Claude Opus 4.6 사용량 관리 가이드
- Anthropic Community — "Managing token limits in Claude agentic workflows", 2026
- Medium — "Why LLMs Appear to Degrade Over Time: Model Drift, Cost Optimization, and Context Rot", 2025
- Tom's Guide — "Gemini 3.1 Pro: Performance vs Stability Tradeoffs", 2026
💡 More from AI Learnings
View all→[AI 개발 자동화] Gemini CLI Superpowers 완벽 가이드 및 실전 유스케이스
단순한 터미널 챗봇을 완벽하게 규율 잡힌 시니어 엔지니어로 바꿔주는 Gemini CLI Superpowers 확장의 14가지 핵심 스킬과 실전 활용법을 소개합니다.
[Antigravity 활용 가이드 3] 오픈소스 Skill로 코딩 자동화 파이프라인 구축하기
Gemini CLI의 꽃이라 할 수 있는 Skill 시스템을 이해하고, 오픈소스로 공개된 다양한 스킬을 확장하여 강력한 코딩 자동화 워크플로우를 구축하는 방법을 알아봅니다.
[AI 개발의 미래] Gemini CLI Superpowers vs Antigravity 에이전트 전격 비교
최근 인공지능(AI) 코딩 어시스턴트 시장은 단순한 '코드 자동 완성' 시대를 넘어, 개발자의 워크플로우를 주도적으로 설계하고 실행하는 **'에이전트 기반(Agentic) 개발'** 시대로 접어들었습니다 [1]. 그 중심에는 터미널 환경을 AI 통합 워크스페이스로 변모...
[AI 개발의 혁신] FastMCP란 무엇이며, 왜 사용해야 하는가?
**MCP(Model Context Protocol)**는 대규모 언어 모델(LLM)을 외부 데이터 소스 및 도구와 안전하게 연결해주는 개방형 표준 프로토콜로, 종종 'AI를 위한 USB-C 포트'에 비유됩니다 [1, 2]. 하지만 이 프로토콜의 스펙을 직접 구현하는...
Model Context Protocol (MCP) 완벽 가이드: AI 에이전트 통합의 새로운 표준
**Model Context Protocol (MCP)**는 2024년 11월 Anthropic이 발표한 오픈 소스 표준으로, AI 애플리케이션이 외부 시스템 및 데이터 소스와 원활하고 안전하게 연결될 수 있도록 돕는 범용 프로토콜입니다 [1], [2]. 과거에는 A...
[Antigravity 활용 가이드 2] 토큰 한계를 넘는 비법: YOLO 모드와 청킹(Chunking)
Gemini CLI의 강력한 기능인 YOLO 모드를 활용한 브레인스토밍 이터레이션 기법과 제한된 컨텍스트 윈도우를 효율적으로 극복하는 청킹(Chunking) 기술을 소개합니다.
[Antigravity 활용 가이드 1] Antigravity와 Gemini CLI, 어떻게 다르게 써야 할까?
Agentic AI 코딩 어시스턴트인 Antigravity와 강력한 터미널 도구인 Gemini CLI의 차이점을 알아보고, 각 도구를 어떤 상황에서 어떻게 활용해야 완벽한 시너지를 낼 수 있는지 분석합니다.