쓰레기를 넣으면 쓰레기가 나온다: 240만 명을 조사하고도 틀린 1936년 대선 여론조사 (Sampling Bias)
빅데이터 시대를 살아가며 우리는 흔히 "데이터는 많으면 많을수록 좋다(More is better)"고 착각합니다. 하지만 통계학의 역사는 아주 단호하게 이렇게 경고합니다.
"대표성 없는 1억 개의 쓰레기 데이터보다, 대표성을 갖춘 1천 개의 데이터가 훨씬 낫다."
오늘은 데이터의 크기에 집착하다가 파멸을 맞이한 잡지사와, 통계학의 정석을 보여주며 여론조사의 전설로 등극한 한 통계학자의 극적인 1936년 미국 대선 이야기를 들려드리겠습니다.
📰 1. 여론조사의 제왕, 리터러리 다이제스트의 몰락
1936년 미국 대통령 선거는 민주당의 프랭클린 D. 루스벨트(Franklin D. Roosevelt) 현 대통령과 공화당의 앨프 랜던(Alf Landon) 후보의 맞대결이었습니다.
당시 미국에는 여론조사 분야의 절대 권력자가 있었습니다. 바로 주간지 «리터러리 다이제스트(The Literary Digest)»였습니다. 이 잡지사는 1920년부터 무려 4번의 대선 결과를 한 번의 오차도 없이 정확하게 맞혀내며 국민적인 신뢰를 얻고 있었습니다.
 리터러리 다이제스트 잡지
(당시 엄청난 권위를 자랑하던 리터러리 다이제스트 잡지. 출처: Wikimedia Commons)
리터러리 다이제스트 잡지
(당시 엄청난 권위를 자랑하던 리터러리 다이제스트 잡지. 출처: Wikimedia Commons)
1936년에도 그들은 엄청난 스케일의 조사를 단행했습니다. 무려 1,000만 장의 모의 투표용지를 전국에 우편으로 발송했고, 그중 240만 장이 회수되었습니다. 현대의 여론조사 표본이 보통 1,000명 수준인 것을 생각하면 240만 명이라는 숫자는 전무후무한, 그야말로 압도적인 '빅데이터'였습니다.
회수된 240만 명의 데이터를 분석한 잡지사는 자신만만하게 표지를 장식했습니다. "공화당 앨프 랜던의 57% 압승 예상!"
🗳️ 2. 충격적인 결과: 데이터가 거짓말을 하다
선거 결과는 어땠을까요? 뚜껑을 열어보니 공화당의 랜던이 압승하기는커녕, 루스벨트가 전체 48개 주 가운데 무려 46개 주를 싹쓸이하며 60% 이상의 득표율로 미국 역사상 유례없는 대승을 거두었습니다.
 프랭클린 D. 루스벨트
(압도적인 지지율로 재선에 성공한 루스벨트 대통령. 출처: Wikimedia Commons)
프랭클린 D. 루스벨트
(압도적인 지지율로 재선에 성공한 루스벨트 대통령. 출처: Wikimedia Commons)
240만 명이라는 엄청난 데이터를 바탕으로 한 «리터러리 다이제스트»의 예측은 완벽하게 빗나갔고, 그들은 신뢰도를 모두 잃은 채 불과 2년 뒤 파산하여 역사 속으로 사라지고 말았습니다.
도대체 240만 명의 데이터는 어디서부터 잘못된 것이었을까요?
📉 3. 표본 추출 편향 (Sampling Bias)의 치명적 함정
원인은 바로 '표본 추출 편향(Sampling Bias)'에 있었습니다. 잡지사가 1,000만 장의 우편물을 보내기 위해 주소를 수집한 곳이 문제였습니다. 그들은 '전화번호부'와 '자동차 등록 명부', 그리고 자사 잡지 정기 구독자 명단을 사용했습니다.
당시 1936년은 미국이 대공황(Great Depression)의 한가운데 있던 시절입니다. 그 시절에 집에 전화기가 있고 자동차를 굴릴 수 있는 사람은 상류층과 부유층뿐이었습니다. 그리고 미국의 부유층은 전통적으로 보수 성향의 공화당(랜던 후보) 지지자였습니다.
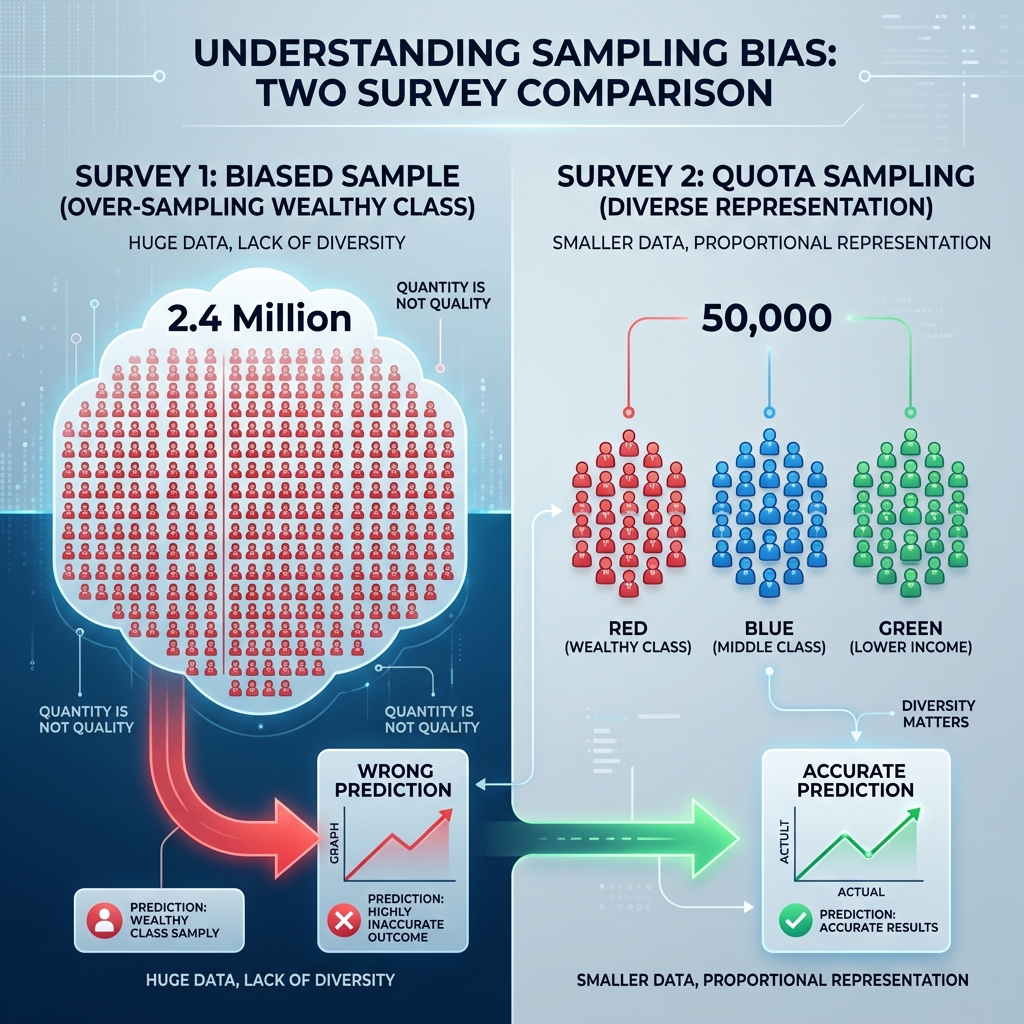 표본 추출 편향 시각화 인포그래픽
(수백만 개의 데이터라도 한쪽 계층에 편중되면 완전히 잘못된 결과를 낳는다. 반면 데이터가 작아도 모집단의 비율을 정확히 반영하면 예측은 적중한다.)
표본 추출 편향 시각화 인포그래픽
(수백만 개의 데이터라도 한쪽 계층에 편중되면 완전히 잘못된 결과를 낳는다. 반면 데이터가 작아도 모집단의 비율을 정확히 반영하면 예측은 적중한다.)
반면, 대공황의 직격탄을 맞아 전화도 차도 없었던 수천만 명의 노동자와 빈민층은 루스벨트의 뉴딜(New Deal) 정책을 열렬히 지지했습니다. 하지만 이들의 목소리는 잡지사의 '240만 명 데이터' 안에 단 한 명도 포함되지 못했습니다.
잡지사는 미국 전체 국민의 의견을 들은 것이 아니라, '공화당을 지지하는 부자들' 240만 명에게만 의견을 물어본 셈이었습니다. 통계학에서는 이를 "쓰레기를 넣으면 쓰레기가 나온다 (Garbage In, Garbage Out)"라고 부릅니다.
🌟 4. 데이터의 '크기'를 이긴 '비율': 조지 갤럽의 등장
이 참담한 실패의 한가운데서, 통계학 역사에 길이 남을 영웅이 등장합니다. 바로 현대 여론조사의 아버지라 불리는 조지 갤럽(George Gallup)입니다.
 조지 갤럽
(여론조사의 전설이 된 조지 갤럽. 출처: Wikimedia Commons)
조지 갤럽
(여론조사의 전설이 된 조지 갤럽. 출처: Wikimedia Commons)
당시 30대의 젊은 통계학자였던 갤럽은 «리터러리 다이제스트»가 240만 명을 조사할 때, 고작 5만 명의 데이터만으로 루스벨트의 당선을 정확하게 예측해 냈습니다.
비결은 '할당 추출법(Quota Sampling)'이었습니다. 갤럽은 무식하게 사람 수만 늘리지 않았습니다. 그는 미국 전체 인구의 성별, 연령, 직업, 소득 수준의 비율을 정확히 계산했습니다. 그리고 그 비율에 맞추어 의도적으로 가난한 사람, 부유한 사람, 백인, 흑인, 농부, 공장 노동자에게 골고루 설문조사를 진행했습니다.
5만 명의 데이터는 240만 명에 비하면 50분의 1에 불과한 초라한 숫자였지만, 그 안에는 '작은 미국'이 완벽한 비율로 축소되어 담겨 있었습니다.
결국 데이터의 절댓값(크기)이 아니라 데이터의 대표성(Quality)이 여론조사의 승패를 가른 것입니다.
💡 5. 비즈니스 리더들을 위한 데이터 리터러시 교훈
1936년의 교훈은 빅데이터가 넘쳐나는 오늘날의 비즈니스 현장에도 똑같이 적용됩니다.
- 로그 데이터의 함정: "우리 앱에 하루 100만 명의 클릭 데이터가 쌓이고 있으니 이 데이터를 믿으면 돼!"라고 생각할 수 있습니다. 하지만 그 100만 명이 특정 이벤트 체리피커(Cherry-picker)나 특정 연령대에 편중되어 있다면, 그 데이터로 내린 신사업 결정은 참사를 부릅니다.
- 리뷰 분석의 맹점: 상품의 평점이나 리뷰 1만 개를 텍스트 마이닝하여 고객 만족도를 분석했다고 합시다. 하지만 보통 리뷰는 '극도로 만족한 사람'이나 '극도로 분노한 사람'만 작성합니다. 대다수의 '침묵하는 보통 고객'의 의견은 표본에서 누락(Sampling Bias)되어 있습니다.
거대한 대시보드와 수천만 건의 데이터를 바라볼 때, 우리는 항상 스스로에게 물어야 합니다. "이 거대한 데이터 더미 안에, 혹시 전화기 없는 사람들의 목소리가 빠져있지는 않은가?"
[참고 문헌]
- Squire, P. (1988). "Why the 1936 Literary Digest Poll Failed". Public Opinion Quarterly.
- Gallup, G. (1972). "The Sophisticated Poll Watcher's Guide". Princeton Opinion Press.
A/B 테스트와 통계적 유의성의 함정: p-value의 진실과 가짜 승리(False Positive) 피하기
현대 디지털 비즈니스에서 직관에 의존한 의사결정은 도박과 같습니다. 넷플릭스, 구글, 아마존과 같은 기업들이 성장을 멈추지 않는 이유는 천재적인 기획자 덕분이 아니라, 수천 개의 가설을 동시에 검증하는 강력한 **A/B 테스트(A/B Testing)** 인프라 덕분입니...
Vibe Coding 기반 광고 낭비 감시 자동화 시스템 구축 (n8n, Antigravity)
지금까지 11편의 포스트를 통해 디지털 마케팅에 숨겨진 거대한 예산 낭비 구멍(Cannibalization, MFA, 봇 트래픽, PMax 블랙박스 등)을 파헤쳤습니다. 이론을 알았다면 이제 남은 것은 단 하나, **실행(Execution)**입니다. 하지만 데이터 엔...
AI에 끌려가지 않는 '신호 설계자(Signal Designer)' 전략
구글 PMax(Performance Max)나 메타 Advantage+와 같은 극단적 자동화 캠페인의 시대입니다. 타겟팅, 입찰, 게재 위치 심지어 광고 소재 조립까지 AI가 다 알아서 해주는 세상에서 **"마케터의 새로운 역할은 무엇인가?"**라는 질문이 쏟아지고 있...
전문가도 속는 통계 오류: 상관/인과, 교란 변수, 유의성의 함정
"데이터는 거짓말을 하지 않는다." 마케터들이 흔히 하는 착각입니다. 데이터 자체는 거짓말을 하지 않을지 몰라도, **그 데이터를 해석하는 사람은 매일 거짓말에 속아 넘어갑니다.** 오늘은 마케터의 데이터 리터러시(Data Literacy)를 시험하는 가장 무서운 통계...
우리가 믿었던 '공부법'의 배신: 데이터가 폭로한 3가지 학습 신화
"사람은 각자 타고난 학습 스타일이 있다." "교과서에 형광펜으로 밑줄을 그으며 반복해서 읽는 것이 최고다." "어떤 분야든 1만 시간을 투자하면 세계적인 전문가가 될 수 있다." 우리는 살면서 이런 조언들을 무수히 듣고 자랐습니다. 하지만 데이터와 인지과학의 세계...
8만 명 중 1등 — 한국 대학생이 세계 퀀트 대회를 제패한 '32개 알고리즘'의 비밀
142개국 8만 명이 참가한 국제 퀀트 챔피언십(IQC)에서 UNIST 김민겸 학생이 한국인 최초로 우승했다. 200개 넘는 알고리즘 대신 32개만 쓴 그의 전략, 그리고 AI 시대 퀀트 투자의 본질을 분석한다.
하루 8잔? 물에 관한 가장 유명한 건강 신화의 탄생과 붕괴
우리가 수십 년간 믿어온 '하루 물 8잔' 규칙은 어디서 왔을까요? 1945년 단 하나의 보고서에서 시작된 거대한 오해가 과학, 미디어, 상업적 이해관계를 거쳐 어떻게 '건강 상식'으로 둔갑했는지, 그리고 누가 이 신화를 무너뜨렸는지 추적합니다.